
Using the Hypothesis
Test in Excel To Find
Out If Delivery Times
Have Gotten Worse
This article will explain how to use Excel to perform a Hypothesis Test to analyze delivery time for a business (a furniture store) has gotten worse. Specifically, we will show how to use Excel to perform One-Tailed, One-Sample, Unpaired Hypothesis Test of Mean to determine whether a furniture company's delivery time really has gotten worse.
This Hypothesis Test will be testing the Null Hypothesis that delivery time has not changed.
The advantages of statistical analysis in Excel to solve business statistics problems is that most problems can be solved in just one or two steps and there is no more need to look anything up on Normal Distribution tables.
Here is the problem:
Problem: A furniture company states that its average delivery time is 15 days with a (population) standard deviation of 4 days. A random sample of 50 deliveries showed an average delivery time of 17 days. Determine within 98% certainty (0.02 significance level) whether delivery time has increased.
Here is the Before and After data for the delivery times:
"Before Data"
µ = "Before Data" mean = 15
σ = "Before Data" population standard deviation = 4
"After Data"
xavg = "After Data" sample average = 17
n = "After Data" Sample size = 50
α = Level of Significance = 0.02
Therefore there is 2% Max chance of error.
Therefore there is a 98% Level of Certainty Required.
Before we begin solving this problem, we need to know whether we are dealing with normally distributed data. If the data is not normally distributed, we have to use nonparametric statistical tests to solve this problem.
Always Test for Normality First
Normality tests should be performed on the before and after delivery time data. Both data sets must be normally distributed to perform the well-known hypothesis test that is based upon the underlying data being normally distributed. This blog has numerous articles about how to perform normality testing and nonparametric testing if the data is not normally distributed.
The MOST Important Step
Determine What Type of Hypothesis
Test You Will Perform
1) Hypothesis Test of Mean or Proportion?
We know that this is a test of mean and not proportion because each individual sample taken can have a wide range of values: Any delivery time sample measurement from 12 to 18 days is probably reasonable.
2) One or Two-Tailed Hypothesis Test?
We know that this is a one-tailed test because we are trying to determine if the "After Data" mean delivery time is larger (worse) than the "Before Data" mean delivery time, not whether the mean mean delivery time is merely different, which would be a two-tailed test.
3) One or Two-Sample Hypothesis Test?
We know that only one sample needs to be taken because the population data being tested is already available.
4) Paired or Unpaired Hypothesis Test?
This is unpaired data because groups are sampled independently.
In this case, we are performing a One-Tailed, One-Sample, Unpaired Hypothesis Test of Mean to determine whether a furniture store's mean delivery time has really gotten worse. We will do this test in Excel. It is extremely important to establish the type of Hypothesis test. Each type of Hypothesis test uses a slightly (or very) different methodology and set of formulas.
The Four-Step Method That Solves ALL Hypothesis Tests
This problem can be solved using the standard four-step method for Hypothesis testing.
Step 1 - Create the Null and Alternate Hypotheses
The Null Hypothesis normally states that both means are the same.If the "Before Data" population mean, µ, equals the "After Data" sample mean, xavg, then xavg = µ = 15
The Null Hypothesis states that both Before and After mean delivery times are the same, which is equivalent to:
The Null Hypothesis, which states that xavg is the same as µ (which is 15), is as follows:Null Hypothesis, H0, is: xavg = 15
*********************************
The Alternate Hypothesis states that the After Data mean delivery time is larger, which is equivalent to:
The Alternate Hypothesis, which states that xavg is larger than µ (which is 15), is as follows::
Alternate Hypothesis, H1 is: xavg is greater than 15
*********************************
For this one-tailed test, the Alternative Hypothesis states that the value of the distributed variable xavg is larger than the value of 15 stated in the Null Hypothesis,
The Region of Uncertainty will be entirely in the right outer tail.
Note - the Alternative Hypothesis determines whether the Hypothesis test is a one-tailed test or a two-tailed test as follows:
One-tailed test - (Value of variable) is greater than OR is less than (Constant)
Two-tailed test - (Value of variable) does not equal (Constant)
Step 2 - Map the Normal Curve
We now create a Normal curve showing a distribution of the same variable that is used by the Null Hypothesis, which is xavg.
The mean of this Normal curve will occur at the same value of the distributed variable as stated in the Null Hypothesis.
Since the Null Hypothesis states that xavg = 15, the Normal curve will map the distribution of the variable xavg with a mean of xavg = 15.
************************************
This Normal curve will have a standard error that is calculated as the standard error of a sample taken from a population is normally calculated, as follows:
Sample Standard Error = sxavg = s / SQRT(n) = 4 / SQRT(50) = 0.566
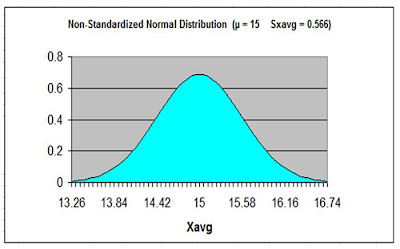

Click On Image To See Larger Version
Step 3 - Map the Region of Certainty
The problem requires a 98% Level of Certainty so the Region of Certainty will contain 98% of the area under the Normal curve.
We know that this problem uses a one-tailed test with the Region of Uncertainty entirely contained in the outer right tail.
The Region of Uncertainty contains 2% of the total area under the Normal curve. The entire 98% Region of Certainty lies to the left of the 2% Region of Uncertainty, which is entirely contained in the outer right tail.
****************************************
We need to find out how far the boundary of the Region of Certainty is from the Normal curve mean. Calculating the number of standard errors from the Normal curve mean to the outer boundary of the Region of Certainty in the right tail for a one-tailed test is done as follows:
z98%,1-tailed = NORMSINV(1 - α) = NORMSINV(0.98) = 2.05
Excel Note - NORMSINV(x) = The number of standard errors from the Normal curve mean to a point right of the Normal curve mean at which x percent of the area under the Normal curve will be to the left of that point.
Additional note - For a one-tailed test, NORMSINV(x) can be used to calculate the number of standard errors from the Normal curve mean to the boundary of the Region of Certainty whether it is in the left or the right tail.
Additional note - For a one-tailed test, NORMSINV(x) can be used to calculate the number of standard errors from the Normal curve mean to the boundary of the Region of Certainty whether it is in the left or the right tail.
The Region of Certainty extends to the right of the Normal curve mean of xavg = 15 by 2.05 standard errors.
One standard error = sxavg = 0.566, so:
2.05 standard errors = (2.05) * (0.566) = 1.16
The outer boundary of the Region of Certainty has the value = µ + z95%,one-tailed * sxavg
which equals 15 + (2.05) * (0.566) = 15 + 1.16 = 16.16

Click Image To See Larger Version
The point, 16.16, is 2.05 standard errors from the Normal curve mean of xavg = 15This point, 16.16, is the right boundary of the 98% Region of Certainty on the Normal curve.
Step 4 - Perform Critical Value and p-Value Tests
a) Critical Value Test
The Critical Value Test is the final test to determine whether to reject or not reject the Null Hypothesis. The p Value Test, described next, is an equivalent alternative to the Critical Value Test.
The Critical Value test tells whether the value of the actual variable, xavg, falls inside or outside of the Critical Value, which is the boundary between the Region of Certainty and the Region of Uncertainty.
If the actual value of the distributed variable, xavg, falls within the Region of Certainty, the Null Hypothesis is not rejected.
If the actual value of the distributed variable, xavg, falls outside of the Region of Certainty and, therefore, into the Region of Uncertainty, the Null Hypothesis is rejected and the Alternate Hypothesis is accepted.
The actual value of the variable xavg = 17 and is therefore to the right of (outside of) the outer right Critical Value (16.16), which is the boundary between the Regions of Certainty and Uncertainty in the right tail.
The actual value of the variable xavg is outside the Region of Certainty and therefore outside the Critical Value.
We therefore reject the Null Hypothesis and accept the Alternate Hypothesis which states that average delivery time has increased, with a maximum possible error of 2%.

Click On Image To See Larger Version
b) p Value Test
The p Value Test is an equivalent alternative to the Critical Value Test and also tells whether to reject or not reject the Null Hypothesis.
The p Value equals the percentage of area under the Normal curve that is in the tail outside of the actual value of the variable xavg.
For a one-tailed test, if the p Value is larger than α, the Null Hypothesis is not rejected.
For a two-tailed test, if the p Value is larger than α/2, the Null Hypothesis is not rejected.
For a one-tailed test, the Region of Uncertainty is contained entirely in one tail. Therefore the curve area contained by the Region of Uncertainty in that tail equals α.
For a two-tailed test, the Region of Uncertainty is split between both tails. Therefore the curve area contained by the Region of Uncertainty in that tail equals α/2.
The p Value for the actual value of the distributed variable, which in this case is greater than the mean (falls to the right of the mean in the right tail), is:
p Valuexavg = 1 - NORMSDIST( [ xavg - µ ] / sxavg )
Excel note - NORMSDIST(x) calculates the total area under the Normal curve to the LEFT of the point that is x standard errors to the right of the Normal curve mean. Since we are calculating the area to the RIGHT of this point, we use 1 - NORMSDIST..
p Valuexavg = 1 - NORMSDIST((17 - 15 ) / 0.566) = 1 - NORMSDIST(2.0/0.566) = 0.0002
The p Value (0.0002) is less than α (0.02), so the Null Hypothesis is rejected and the Alternate Hypothesis is accepted..
For a one-tailed test - When the p Value is less than α, the actual value of the distributed variable falls outside the Region of Certainty and the Null Hypothesis is rejected.
This is the case here.

Click Image To See Larger Version
*****************************************
Here is a link to this article if you wish to link to it:
Using the Hypothesis Test in Excel to Find Out If Your Delivery Time Has Gotten Worse
Using the Hypothesis Test in Excel to Find Out If Your Delivery Time Has Gotten Worse
If You Like This, Then Share It...


Excel Master Series Blog Directory
Statistical Topics and Articles In Each Topic
- Histograms in Excel
- Bar Chart in Excel
- Combinations & Permutations in Excel
- Normal Distribution in Excel
- Overview of the Normal Distribution
- Normal Distribution’s PDF (Probability Density Function) in Excel 2010 and Excel 2013
- Normal Distribution’s CDF (Cumulative Distribution Function) in Excel 2010 and Excel 2013
- Solving Normal Distribution Problems in Excel 2010 and Excel 2013
- Overview of the Standard Normal Distribution in Excel 2010 and Excel 2013
- An Important Difference Between the t and Normal Distribution Graphs
- The Empirical Rule and Chebyshev’s Theorem in Excel – Calculating How Much Data Is a Certain Distance From the Mean
- Demonstrating the Central Limit Theorem In Excel 2010 and Excel 2013 In An Easy-To-Understand Way
- t-Distribution in Excel
- Binomial Distribution in Excel
- z-Tests in Excel
- t-Tests in Excel
- Overview of t-Tests: Hypothesis Tests that Use the t-Distribution
- 1-Sample t-Tests in Excel
- Overview of the 1-Sample t-Test in Excel 2010 and Excel 2013
- Excel Normality Testing For the 1-Sample t-Test in Excel 2010 and Excel 2013
- 1-Sample t-Test – Effect Size in Excel 2010 and Excel 2013
- 1-Sample t-Test Power With G*Power Utility
- Wilcoxon Signed-Rank Test As a 1-Sample t-Test Alternative in Excel 2010 and Excel 2013
- Sign Test As a 1-Sample t-Test Alternative in Excel 2010 and Excel 2013
- 2-Independent-Sample Pooled t-Tests in Excel
- Overview of 2-Independent-Sample Pooled t-Test in Excel 2010 and Excel 2013
- Excel Variance Tests: Levene’s, Brown-Forsythe, and F Test For 2-Sample Pooled t-Test in Excel 2010 and Excel 2013
- Excel Normality Tests Kolmogorov-Smirnov, Anderson-Darling, and Shapiro Wilk Tests For Two-Sample Pooled t-Test
- Two-Independent-Sample Pooled t-Test - All Excel Calculations
- 2-Sample Pooled t-Test – Effect Size in Excel 2010 and Excel 2013
- 2-Sample Pooled t-Test Power With G*Power Utility
- Mann-Whitney U Test in Excel as 2-Sample Pooled t-Test Nonparametric Alternative in Excel 2010 and Excel 2013
- 2-Sample Pooled t-Test = Single-Factor ANOVA With 2 Sample Groups
- 2-Independent-Sample Unpooled t-Tests in Excel
- 2-Independent-Sample Unpooled t-Test in Excel 2010 and Excel 2013
- Variance Tests: Levene’s Test, Brown-Forsythe Test, and F-Test in Excel For 2-Sample Unpooled t-Test
- Excel Normality Tests Kolmogorov-Smirnov, Anderson-Darling, and Shapiro-Wilk For 2-Sample Unpooled t-Test
- 2-Sample Unpooled t-Test Excel Calculations, Formulas, and Tools
- Effect Size for a 2-Independent-Sample Unpooled t-Test in Excel 2010 and Excel 2013
- Test Power of a 2-Independent Sample Unpooled t-Test With G-Power Utility
- Paired (2-Sample Dependent) t-Tests in Excel
- Paired t-Test in Excel 2010 and Excel 2013
- Excel Normality Testing of Paired t-Test Data
- Paired t-Test Excel Calculations, Formulas, and Tools
- Paired t-Test – Effect Size in Excel 2010, and Excel 2013
- Paired t-Test – Test Power With G-Power Utility
- Wilcoxon Signed-Rank Test As a Paired t-Test Alternative
- Sign Test in Excel As A Paired t-Test Alternative
- Hypothesis Tests of Proportion in Excel
- Hypothesis Tests of Proportion Overview (Hypothesis Testing On Binomial Data)
- 1-Sample Hypothesis Test of Proportion in Excel 2010 and Excel 2013
- 2-Sample Pooled Hypothesis Test of Proportion in Excel 2010 and Excel 2013
- How To Build a Much More Useful Split-Tester in Excel Than Google's Website Optimizer
- Chi-Square Independence Tests in Excel
- Chi-Square Goodness-Of-Fit Tests in Excel
- F Tests in Excel
- Correlation in Excel
- Pearson Correlation in Excel
- Spearman Correlation in Excel
- Confidence Intervals in Excel
- Overview of z-Based Confidence Intervals of a Population Mean in Excel 2010 and Excel 2013
- t-Based Confidence Intervals of a Population Mean in Excel 2010 and Excel 2013
- Minimum Sample Size to Limit the Size of a Confidence interval of a Population Mean
- Confidence Interval of Population Proportion in Excel 2010 and Excel 2013
- Min Sample Size of Confidence Interval of Proportion in Excel 2010 and Excel 2013
- Simple Linear Regression in Excel
- Overview of Simple Linear Regression in Excel 2010 and Excel 2013
- Simple Linear Regression Example in Excel 2010 and Excel 2013
- Residual Evaluation For Simple Regression in Excel 2010 and Excel 2013
- Residual Normality Tests in Excel – Kolmogorov-Smirnov Test, Anderson-Darling Test, and Shapiro-Wilk Test For Simple Linear Regression
- Evaluation of Simple Regression Output For Excel 2010 and Excel 2013
- All Calculations Performed By the Simple Regression Data Analysis Tool in Excel 2010 and Excel 2013
- Prediction Interval of Simple Regression in Excel 2010 and Excel 2013
- Multiple Linear Regression in Excel
- Basics of Multiple Regression in Excel 2010 and Excel 2013
- Multiple Linear Regression Example in Excel 2010 and Excel 2013
- Multiple Linear Regression’s Required Residual Assumptions
- Normality Testing of Residuals in Excel 2010 and Excel 2013
- Evaluating the Excel Output of Multiple Regression
- Estimating the Prediction Interval of Multiple Regression in Excel
- Regression - How To Do Conjoint Analysis Using Dummy Variable Regression in Excel
- Logistic Regression in Excel
- Logistic Regression Overview
- Logistic Regression Performed in Excel 2010 and Excel 2013
- R Square For Logistic Regression Overview
- Excel R Square Tests: Nagelkerke, Cox and Snell, and Log-Linear Ratio in Excel 2010 and Excel 2013
- Likelihood Ratio Is Better Than Wald Statistic To Determine if the Variable Coefficients Are Significant For Excel 2010 and Excel 2013
- Excel Classification Table: Logistic Regression’s Percentage Correct of Predicted Results in Excel 2010 and Excel 2013
- Hosmer-Lemeshow Test in Excel – Logistic Regression Goodness-of-Fit Test in Excel 2010 and Excel 2013
- Single-Factor ANOVA in Excel
- Overview of Single-Factor ANOVA
- Single-Factor ANOVA Example in Excel 2010 and Excel 2013
- Shapiro-Wilk Normality Test in Excel For Each Single-Factor ANOVA Sample Group
- Kruskal-Wallis Test Alternative For Single Factor ANOVA in Excel 2010 and Excel 2013
- Levene’s and Brown-Forsythe Tests in Excel For Single-Factor ANOVA Sample Group Variance Comparison
- Single-Factor ANOVA - All Excel Calculations
- Overview of Post-Hoc Testing For Single-Factor ANOVA
- Tukey-Kramer Post-Hoc Test in Excel For Single-Factor ANOVA
- Games-Howell Post-Hoc Test in Excel For Single-Factor ANOVA
- Overview of Effect Size For Single-Factor ANOVA
- ANOVA Effect Size Calculation Eta Squared (?2) in Excel 2010 and Excel 2013
- ANOVA Effect Size Calculation Psi (?) – RMSSE – in Excel 2010 and Excel 2013
- ANOVA Effect Size Calculation Omega Squared (?2) in Excel 2010 and Excel 2013
- Power of Single-Factor ANOVA Test Using Free Utility G*Power
- Welch’s ANOVA Test in Excel Substitute For Single-Factor ANOVA When Sample Variances Are Not Similar
- Brown-Forsythe F-Test in Excel Substitute For Single-Factor ANOVA When Sample Variances Are Not Similar
- Two-Factor ANOVA With Replication in Excel
- Two-Factor ANOVA With Replication in Excel 2010 and Excel 2013
- Variance Tests: Levene’s and Brown-Forsythe For 2-Factor ANOVA in Excel 2010 and Excel 2013
- Shapiro-Wilk Normality Test in Excel For 2-Factor ANOVA With Replication
- 2-Factor ANOVA With Replication Effect Size in Excel 2010 and Excel 2013
- Excel Post Hoc Tukey’s HSD Test For 2-Factor ANOVA With Replication
- 2-Factor ANOVA With Replication – Test Power With G-Power Utility
- Scheirer-Ray-Hare Test Alternative For 2-Factor ANOVA With Replication
- Two-Factor ANOVA Without Replication in Excel
- Creating Interactive Graphs of Statistical Distributions in Excel
- Interactive Statistical Distribution Graph in Excel 2010 and Excel 2013
- Interactive Graph of the Normal Distribution in Excel 2010 and Excel 2013
- Interactive Graph of the Chi-Square Distribution in Excel 2010 and Excel 2013
- Interactive Graph of the t-Distribution in Excel 2010 and Excel 2013
- Interactive Graph of the Binomial Distribution in Excel 2010 and Excel 2013
- Interactive Graph of the Exponential Distribution in Excel 2010 and Excel 2013
- Interactive Graph of the Beta Distribution in Excel 2010 and Excel 2013
- Interactive Graph of the Gamma Distribution in Excel 2010 and Excel 2013
- Interactive Graph of the Poisson Distribution in Excel 2010 and Excel 2013
- Solving Problems With Other Distributions in Excel
- Solving Uniform Distribution Problems in Excel 2010 and Excel 2013
- Solving Multinomial Distribution Problems in Excel 2010 and Excel 2013
- Solving Exponential Distribution Problems in Excel 2010 and Excel 2013
- Solving Beta Distribution Problems in Excel 2010 and Excel 2013
- Solving Gamma Distribution Problems in Excel 2010 and Excel 2013
- Solving Poisson Distribution Problems in Excel 2010 and Excel 2013
- Optimization With Excel Solver
- Maximizing Lead Generation With Excel Solver
- Minimizing Cutting Stock Waste With Excel Solver
- Optimal Investment Selection With Excel Solver
- Minimizing the Total Cost of Shipping From Multiple Points To Multiple Points With Excel Solver
- Knapsack Loading Problem in Excel Solver – Optimizing the Loading of a Limited Compartment
- Optimizing a Bond Portfolio With Excel Solver
- Travelling Salesman Problem in Excel Solver – Finding the Shortest Path To Reach All Customers
- Chi-Square Population Variance Test in Excel
- Analyzing Data With Pivot Tables
- SEO Functions in Excel
- Time Series Analysis in Excel






No comments:
Post a Comment